So, back to the monolith it is then?
By Sam Theisens on 20 mei 2023
Amazon embraces the mighty monolith
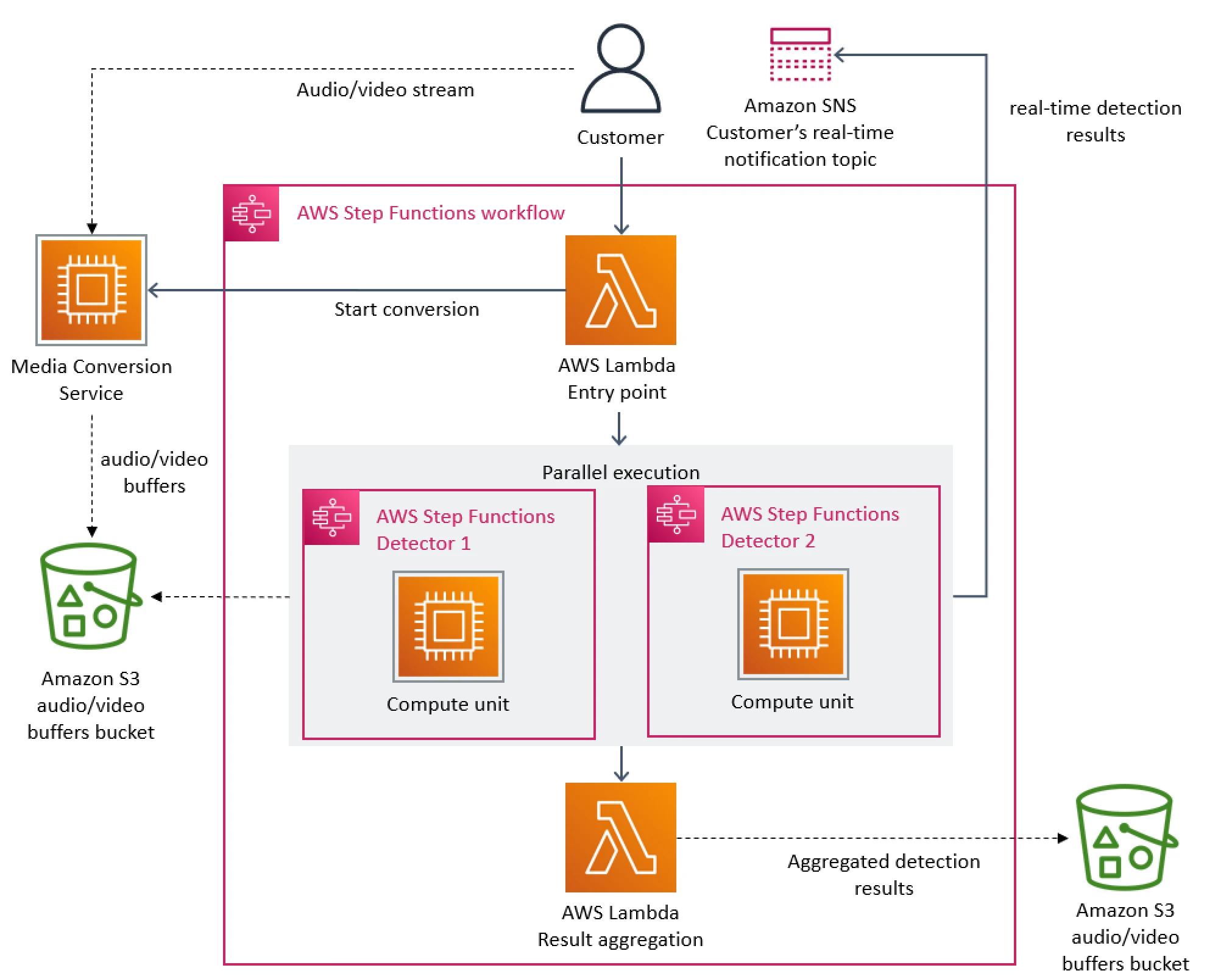
In March 2023, Amazon published a blog post , detailing how they had managed to reduce the cost of their audio-video monitoring service by 90%. The key to this reduction was migrating from a distributed, microservice architecture to a monolith. The blog post went viral, prompting some software industry celebrities to question the entire concept of microservices.
What should we learn from this?
So, does this mean microservices are fundamentally flawed? Should we all migrate back to monoliths? No and definitely no I would say. Instead, my takeaways from this article are:
- Microservices aren't about scaling for performance. At least not primarily. Although horizontally scalability for computationally intensive operations can be very useful or even essential in some cases, it tends to be a rare benefit. Very often, performance bottlenecks are IO bound and caused by external systems beyond your control. Nevertheless, there are other compelling reasons to consider microservices: they force you to communicate via contracts, encourage you to organize your functionality around domains, and allow you to scale your organization. Of course, all this comes at considerable costs. There's no free lunch 👇.
- Don't underestimate the power of a single CPU in 2023. To judge whether a process is unreasonably slow or not, I tend to think of the fact that already in the 1990s, screens showed 65K pixels at any given time. Back then, multiple arithmetic calculations (additions, subtractions) could be performed for each pixel, fifty times per second. Nowadays, your screen probably displays more than 5 Million pixels at once. So, if the amount of datapoints you are dealing with in the order of millions, you should generally be able to process them in a matter of seconds on a single machine. If you can't, you may be doing something very inefficient.
- Software engineering is hard. Mistakes are made all the time, everywhere. Even at the big 4 tech companies. Kudos to Amazon 👏 for openly sharing the mistake they made so that we may all learn.
In the next section I will share one of our own experiences, not entirely different from the Amazon example.
The 90% cost reduction case at Vandebron
Microservices or just distributed computing?
Considering that all the functionality used in the Amazon case belongs to the same domain, it arguably does not even serve as
a case against improper use of microservices, but instead a case against misuse distributed computing.
Let's look into an example of misuse of distributed computing at Vandebron now.
Predicting the production of electricity
For utility companies, accurately predicting both electricity consumption and production is crucial. Failing to do so can result in blackouts or overproduction, both of which are very costly. Vandebron is a unique utility company in that the electricity that our customers consume is produced by a very large amount of relatively small scale producers, who produce electricity using windmills or solar panels. The large number and the weather dependent nature of these producers make it very hard to predict electricity generation accurately.
To do this, we use a machine learning model that is trained on historical production data and predictions from the national weather institute. As you can imagine, this is a computationally intensive task, involving large amounts of data. Fortunately, we have tooling in place that allows us to distribute computations of a cluster of machines if the task is too large for a single machine to handle.
However, here's the catch: the fact that we can distribute computations does not mean that we should. Initially it seemed that we couldn't analyze the weather data quick enough for the estimation of our production to still be a prediction rather than a postdiction. We decided to distribute the computation of the weather data over a cluster of machines. This worked, but it made our software more complex and Jeff Bezos even richer than he already was.
Upon closer inspection, we found an extreme inefficiency in our code. It turned out that we were repeatedly reading the entire weather dataset into memory, for every single "pixel". After removing this performance bug, the entire analysis could easily be done on a single machine.
What more is there to say?
So if microservices aren't about performance, what are they about? If I had to sum it up in one sentence It would be:
Microservices are a way to scale your organization
There is a lot of detail hiding in that sentence, which I can't unpack in the scope of this article. If you're interested what microservices have meant for us, I would recommend you watch the presentation below.
Microservices at Vandebron
At Vandebron, we jumped onto the "microservice bandwagon" circa 2019. This wasn't a decision made on a whim. We had seen a few industry trends come and go, so we first read up and did our own analysis. We found that the concept of microservices held promise, but also knew that they would come at a cost.
These are some of the dangers we identified and what we did to mitigate them.
| Danger | Mitigation |
| A stagnating architecture | Compile and unit-test time detection of breaking changes |
| Complicated and error prone deployments | Modular CI/CD pipelines |
| Team siloization | A single repository (AKA monorepo) for all microservices and a discussion platform for cross-domain and cross-team concerns |
| Duplication of code | Shared in house libraries for common functionality |
The following presentation to the students of VU University, Amsterdam explains how we implemented some of these mitigations and what we learned from them.
