The Why and How of Dagster User Code Deployment Automation
By Pieter Custers on 8 juli 2022
TL;DR
If you want to deploy new Dagster user code respositories, you need to modify and redeploy the whole Dagster system (while they are presented as separate in the docs). This is undesirable for many reasons, most notably because it slows down a migration or the regular development process. This post presents a way to avoid this and build a fully automated CI/CD-pipeline for (new) user code.
This article assumes that:
- you (plan to) host Dagster on Kubernetes and manage its deployment with Helm and Ansible;
- you want to automate the deployment of new Dagster user code repositories with a CI/CD pipeline automation tool of choice;
- and you want to be able to (re)deploy the whole Dagster system and user code from scratch.
Why Dagster?
In short Dagster is a tool to build and orchestrate complex data applications in Python. For us, in the end, Dagster improved the development cycle for things like simple cron jobs as well as for complex ML pipelines. Testing the flows locally was never so easy, for instance. And with features like asset materialization and sensors, we can trigger downstream jobs based on the change of an external state that an upstream job caused, without these jobs having to know of each other's existence.
However, deployment of new user code respositories caused us some CI/CD related headaches...
System and user code are separated
Dagster separates the system deployment - the Dagit (UI) web server and the daemons that coordinate the runs - from the user code deployment - the actual data pipeline. In other words: the user code servers run in complete isolation from the system and each other.
This is a great feature of which the advantages are obvious: user code repositories have their own Python environment, teams can manage these separately, and if a user code server breaks down the system is not impacted. In fact, it even doesn't require a restart when user code is updated!
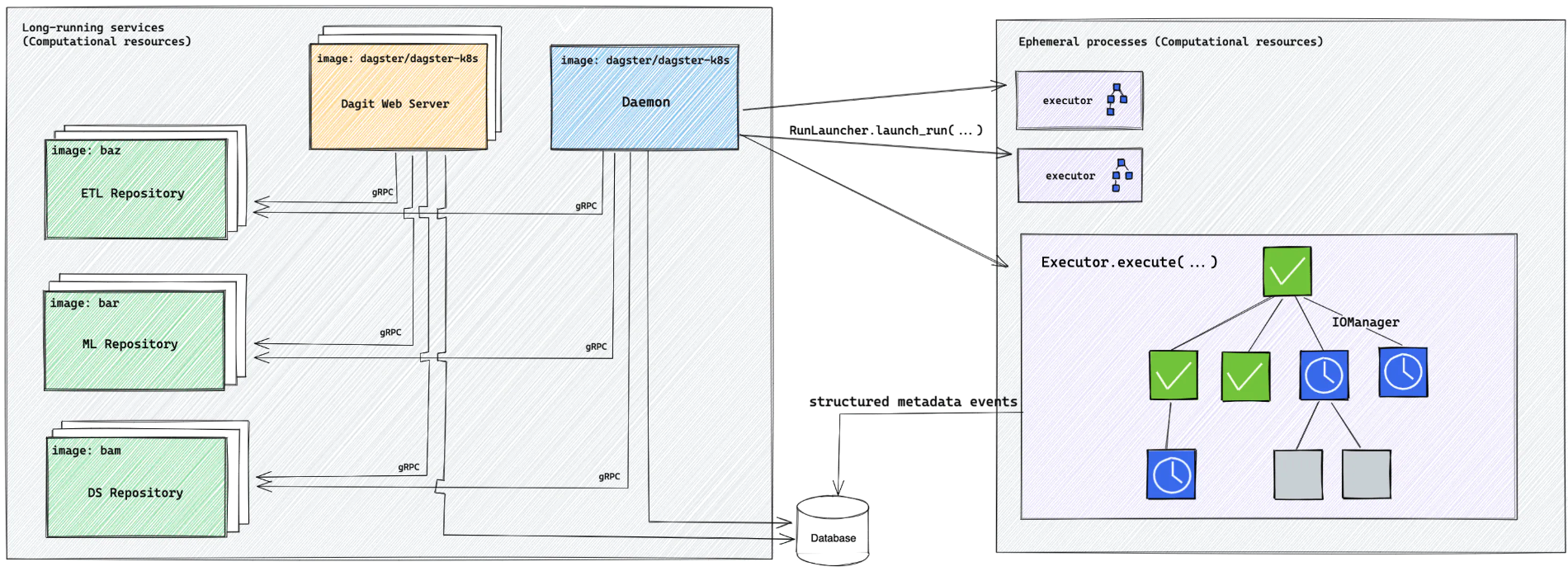
In Helm terms: there are 2 charts, namely the system: dagster/dagster (values.yaml), and the user code: dagster/dagster-user-deployments (values.yaml). Note that you have to set dagster-user-deployments.enabled: true in the dagster/dagster values-yaml to enable this.
Or are they?
That having said, you might find it peculiar that in the values-yaml of the system deployment, you need to specify the user code servers. That looks like this:
workspace: enabled: true servers: - host: "k8s-example-user-code-1" port: 3030 name: "user-code-example"
This means system and user deployments are not actually completely separated!
This implies that, if you want to add a new user code repository, not only do you need to:
- add the repo to the user code's
values.yaml(via a PR in the Git repo of your company's platform team, probably); - do a helm-upgrade of the corresponding
dagster/dagster-user-deploymentschart;
but because of the not-so-separation, you still need to:
- add the user code server to the system's
values.yaml(via that same PR); - and do a helm-upgrade of the corresponding
dagster/dagsterchart.
Formally this is the process to go through. If you are fine with this, stop reading here. It's the cleanest solution anyway. But it is quite cumbersome, so...
If you are in a situation in which new repositories can get added multiple times a day - for instance because you are in the middle of a migration to Dagster, or you want a staging environment for every single PR - then read on.
Give me more details
How it works is that for every new repo Dagster spins up a (gRPC) server to host the user code. The separation is clear here. But the Dagster system also needs to know about these user code servers, and it does so through a workspace-yaml file. If you run Dagit locally it relies on a workspace.yaml file; on Kubernetes it relies on a ConfigMap - a Kubernetes object used to store non-confidential data in key-value pairs, e.g. the content of a file - which they named dagster-workspace-yaml.
This workspace-yaml is the connection between the system and the user code. The fact that the charts are designed as such that this workspace-yaml is created and modified through the system deployment rather than the user code deployment is the reason we need to redeploy the system.
But what if we could modify this workspace-yaml file ourselves? Can we make the system redeployment obsolete? Short answer: we can.
Our solution
Disclaimer: what we present here is a workaround that we'll keep in place until the moment Dagster releases a version in which the Dagster user code deployment is actually completely separated from the system deployment. And it works like a charm.
Remember: the desired situation is that we do not have to edit the values-yaml files (through a PR) and redeploy all of Dagster for every new repo.
First of all, we added an extra ConfigMap in Kubernetes that contains the values.yaml for the dagster/dagster-user-deployments chart. We named it dagster-user-deployments-values-yaml. The fact that this is a ConfigMap is crucial to prevent conflicts (see next section).
With the extra ConfigMap in place, these are the steps when a repo gets added:
- Add the new repo to the
dagster-user-deployments-values-yamlConfigmap. - Helm-upgrade the
dagster/dagster-user-deploymentschart with the content of that ConfigMap. - Add the server to the
dagster-workspace-yamlConfigMap. - Do a rolling restart of the
dagster-dagitanddagster-daemondeployment to pull the latest workspace to these services.
Refresh the workspace in the UI and there it is, your new repo!
Notes:
- The steps above are completely automatable through your favorite CI/CD pipeline automation tool.
- There is no interaction with a (platform team) Git repo.
- The process, unfortunately, still requires a restart of the system in order to pull the latest workspace-yaml to the system services. The daemon terminates, then restarts, and it might cause a short interruption. Note that this is unavoidable if you add a new repo, no matter how you add it. This could be avoided if a reload of the ConfigMap would be triggered upon a change, which is possible but not enabled.
- If you want to make changes to an existing repo (not code changes but server setting changes), you only have to do the first step (and modify instead of add).
How to prevent conflicts
With many of your team members adding new Dagster repositories through an automated CI/CD pipeline, you might face the situation that 2 people are adding a new repo at around the same time.
When this happens, the dagster-user-deployments-values-yaml ConfigMap cannot be uploaded in the first step because Kubernetes demands that you provide the last-applied-configuration when doing an update. If it doesn't match, the upload fails.
This is perfect as we do not want to overwrite the changes of the conflicting flow. You can optionally build in a retry-mechanism that starts over with pulling the ConfigMap again.
How to deploy from scratch
The above does not yet cover how we are able to deploy the Dagster system and user code completely from scratch. Why do we want this? Well, for instance when somebody accidently deletes the dagster namespace for instance. Or hell breaks loose in any other physical or non-physical form. Or when we simply want to bump the Dagster version, actually.
The key to this is that we version both the dagster-user-deployments-values-yaml and dagster-workspace-yaml as a final step to the flow described above (we do it on S3, in a versioned bucket). Whenever we redeploy Dagster (with Ansible) we pull the latest versions and use them to compile both the values-yaml files from it.
How to clean up old repositories
The above described automation adds new repos but doesn't take care of old obsolete repos. The steps for removing a repo are the same for adding one. The exact implementation depends on your situation. You might want to automatically remove PR staging environments after closing a PR, for instance.
Conclusion
Dagster is an incredibly powerful tool that enabled us to build complex data pipelines with ease. This posts explains how we streamlined the CI/CD pipeline for user code respositories, which enabled us to migrate to Dagster very quickly and saves us lots of time on a daily basis.